AxisOps was recently commissioned to create an AI tool for the LegalTech sector, with the aim of helping Case Handlers reduce the amount of time spent reviewing legal documents. The result was an automated pipeline that consumed and analysed the relevant legal documents, and subsequently produced a report with all the information required by a Case Handler to make a decision.
A task that could take up to half an hour could now be done in just a few minutes!
This article describes the core AI technologies used for this project, and how the solution aligns with AxisOps' AI Philosophy.
If you don't know the difference between "AI", "Generative AI" and "Machine Learning", then we highly recommend checking out this previous article.
Table of Contents
The problem and desired solution
At the heart of AxisOps' consultancy-led approach is getting to know a client, learning about their key processes, and examining their pain points. As part of AxisOps' partnership with Sentry Funding, the review of legal documents was identified as a key opportunity for improvement.
With up to a hundred new cases per day, a dozen legal documents per case, and up to 50 pages per document to review, the time spent reading and compiling information from files often exceeded 30 minutes per case for an experienced Case Handler. But what if their workflow could be made more efficient by partially automating the process?
This was a clear opportunity to leverage AI to deliver significant productivity gains, by automating the information extraction process from the vast amounts of legal documents making their way to the Case Handlers' desks.
The vision was simple: use AI to extract the relevant data from the documents, validate the data with references to their origin, and present the information in such a way that the Case Handler can do what they need to do.
Design philosophy
Based on the desired solution, the problem could be broken down into two main parts:
- Document Classification: Firstly, identify the document type. Is it a passport? Is it a bank statement?
- Document Validation: Secondly, conduct analysis specific to that type of document - for example, one would want to extract very different information from a passport versus a mortgage agreement document
Information from both stages can then be collated into a report for a Case Handler to review.
For both classification and validation stages, there are three different types of document to contend with:
- Structured documents: Documents that have an identical structure every time, like a passport or driving licence
- Semi-structured documents: Documents that have a similar layout and size but with slightly different content each time, like energy bills or employment contracts
- Unstructured documents: Documents that are vastly different each time depending on the context, like school essays or surveyor reports
Each type of document requires a different strategy to work with them. For example, the rigidity and predictability of structured documents means that a logic-based software engineering approach can be used to extract information. However, the varied nature of unstructured documents means that assistance from AI is needed. It is therefore important to design an infrastructure that is flexible enough to deal with any type of document.
This approach is consistent with AxisOps' AI Philosophy, whereby the simplest possible solution should be used for any given problem, rather than a "one-size-fits-all" approach.
For this project, there are a variety of documents to assess - a subset of which are shown in the table below. Note how there is a fairly small range of total pages for the semi-structured documents relative to the unstructured ones.
From this small subset of documents alone, it is easy to see how it would take a long time for a Case Handler to review them in detail.
| Document Type | Typical Size | Structure |
|---|---|---|
| Barrister's Opinion | 3-19 pages | Unstructured |
| Expert Report | 2-39 pages | Unstructured |
| Litigation Funding Agreement | 15-21 pages | Semi-structured |
| Solicitor Fee Agreement | 9-52 pages | Unstructured |
| Solicitor's Undertaking | 3-6 pages | Semi-structured |
Another layer of complexity arises from how information is encoded in the documents. Documents are usually in a vector/text based format, whereby a computer programme can trivially extract the text for further analysis. However, a small but significant portion of documents are in an image format (for example, documents copied using a scanner) whereby advanced "Optical Character Recognition" AI software is required to convert the pixel data from the images into text. It is therefore important that the platform should be able to deal with each of these scenarios.
Document classification
The first stage in the document analysis process is to take a file and figure out what it is. For each file, the contents need to be compared with reference files that represent a "typical" document for that class. However, this comparison process is different for structured and unstructured documents.
Classifying structured and semi-structured documents
If a certain document should be identical every time, how would you verify that it is correct? If it is a scanned document (i.e. an image), each pixel could be compared with a reference document to make sure the pixel is identical. If it is a text-based document, each word could be compared one-by-one. If 100% of words/pixels match, then the type of document is confirmed to be the same as the reference document.
However, this method doesn't work for any normal use case, e.g. passports aren't identical because everyone has a different name. Instead of requiring a 100% match, the threshold could potentially be reduced to 70%, but this approach only works if the words are always in the same sequence. By adding a single word to the start of a document, a word-by-word comparison would reduce the score from a 100% match to a 0% match. A more robust method is therefore required that isn't dependent on the order of the words.
A typical strategy for comparing documents is to use "pairwise similarity". This method involves tallying up the frequency of each word in the document and comparing these totals to the reference documents.
For example, imagine a main document and a separate reference document. Each document contains 100 words. Each features the word "the" 25 times, "AI" 20 times, and "is" 15 times. The remaining 40 words are randomised. The resulting similarity score would be at least 60% in this case.
This approach works very well for comparing both structured and semi-structured documents, as the majority of the words used will be the same every time.
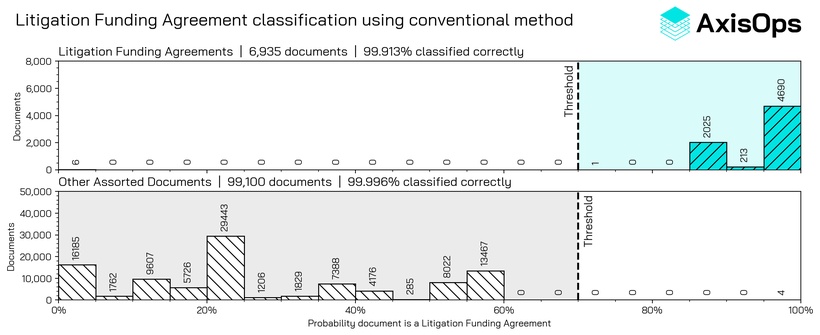
The image below shows the similarity scores for several thousand "Litigation Funding Agreement (LFA)" documents. A similarity threshold of 70% is sufficient to correctly identify over 99.9% of LFA documents, whilst also correctly classifying more than 99.9% of other documents as not being an LFA.
Classifying unstructured documents
The method used for classifying semi-structured text works less well for unstructured documents, as the distribution of words is typically very different for each document. Some reasons for this include:
- Different lengths of documents
- Different topics discussed
- Different writing styles for different authors
A prime example is the "Barrister's Opinion" document, where a barrister will summarise the context and evidence provided for a legal case and give their opinions on the chance of the case succeeding based on various laws and precedents. It is easy to see how this document would be considerably different for every legal case.
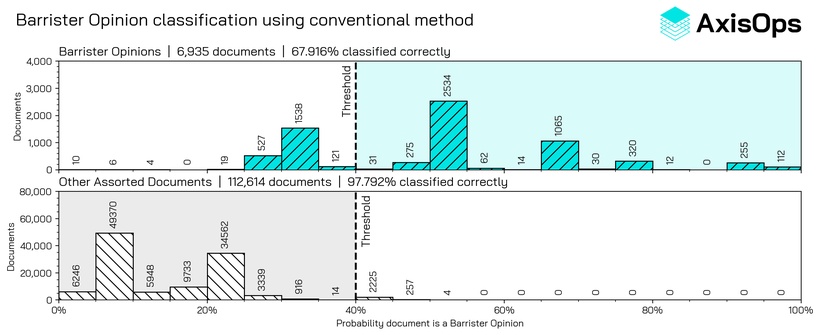
Using the same classification method as used for structured and semi-structured documents, it is not possible to achieve close to a 99% accuracy score for the "Barrister's Opinion", no matter what similarity threshold is used.
To overcome this problem, AxisOps has developed a bespoke AI solution to exploit word patterns in each class of document. For example, given that "Barrister's Opinion" documents are all written by a Barrister, the style of language used is similar each time. This means subtle patterns can be turned into "signals" and subsequently into a similarity prediction.
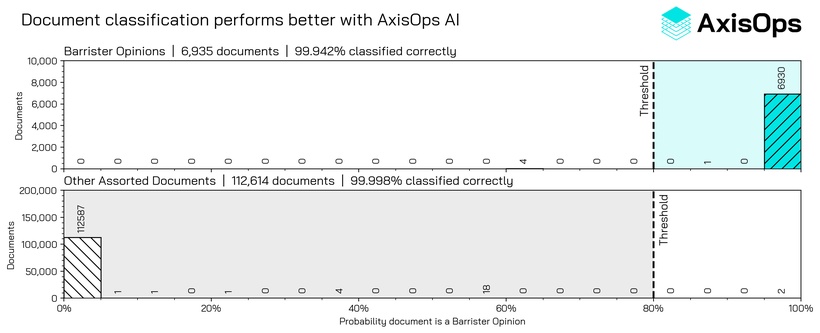
The end result is an AI pipeline that correctly identifies the "Barrister's Opinion" more than 99.9% of the time.
Using the above methods, it is possible to correctly identify all documents in the project with a high degree of accuracy.
| Document Type | Structure | Generic Classification Score | AxisOps AI Classification Score |
|---|---|---|---|
| Barrister's Opinion | Unstructured | 68% | >99% |
| Expert Report | Unstructured | 21% | >99% |
| Litigation Funding Agreement | Semi-structured | >99% | N/A |
| Solicitor Fee Agreement | Unstructured | 90% | 98% |
| Solicitor's Undertaking | Semi-structured | >99% | N/A |
Document validation
Once a document has been classified, it is then possible to extract information specific to that document type, and to verify that the content is valid. Similar to document classification, different methodologies are needed for structured and unstructured documents to achieve the best results.
Validating structured and semi-structured documents
As previously mentioned, part of AxisOps' AI Philosophy is to not use AI wherever possible, ensuring solutions are as robust and transparent as possible. As data always appears in fixed locations within structured documents, this allows traditional software engineering techniques to be used to collect the information.
The same is generally true for semi-structured documents, where there are sufficient "anchor points" from features present in all documents to locate text and features of interest.
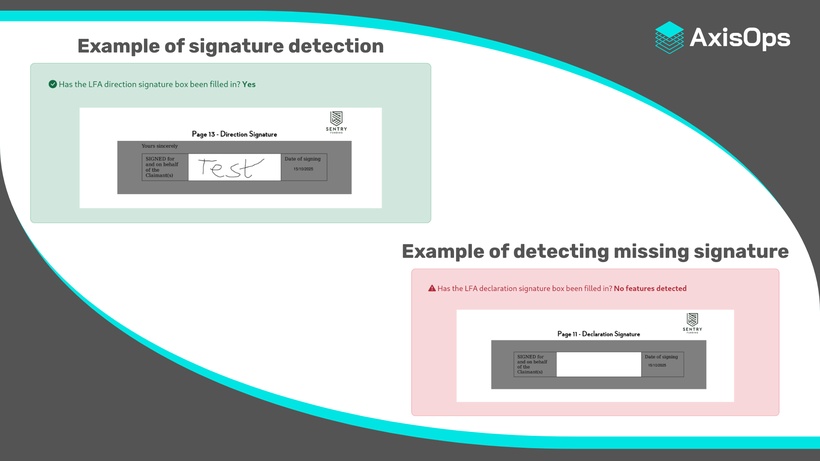
Using the "Litigation Funding Agreement" as an example, a common task is to detect whether the document has been signed. Because the document is semi-structured, the signature box may appear on any page, instead of a fixed location. However, its position can still be identified programmatically, due to its consistent structure and appearance across all documents.
Validating unstructured documents
A purely programmatic approach cannot be used for unstructured documents, as there are simply too few similarities in structure and content to exploit. Until recently, this presented a challenge that couldn't be overcome via standard automation methods. However, through the power of Generative AI it is now possible to work with unstructured data in new and powerful ways.
Large Language Models (LLMs) like ChatGPT and DeepSeek are capable of ingesting large quantities of text and extracting relevant information on request, making them uniquely suitable for handling unstructured documents.
However, the main issue with LLMs is they are prone to hallucinations, where false or inaccurate information can be returned by the AI. For example, a "Barrister's Opinion" document may mention that the chance of a legal case succeeding is 60%, but a hallucinating AI may incorrectly report that the probability is 100%. Mistakes like this are infrequent but can cause serious consequences if they are not caught and handled.
To mitigate these risks, AxisOps has developed an optimised pipeline to improve accuracy, as well as multiple layers of redundancy to validate that an AI output is genuine.
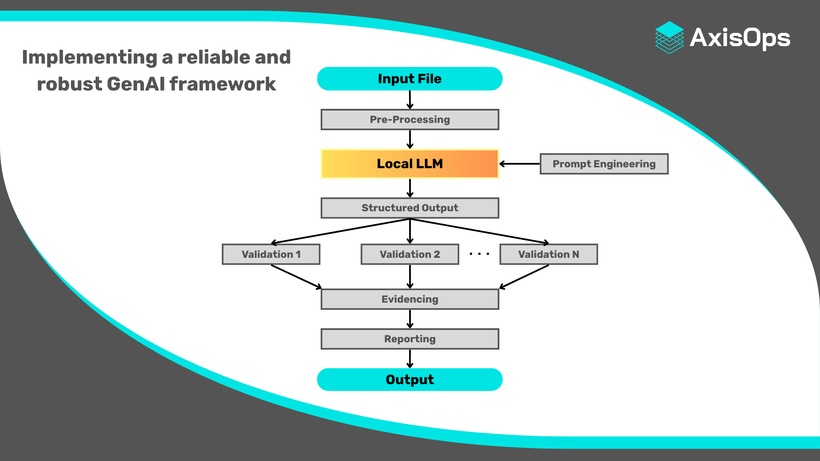
In keeping with AxisOps' data privacy policies, the Large Language Model at the core of the pipeline is hosted on self-managed (sovereign) infrastructure. This means sensitive legal data is not sent to third-party AI service providers. This, in combination with AxisOps' ISO 27001 certification, ensures the data is kept as secure as possible.
Some example statistics for this AI pipeline are shown in the table below, with information extracted from over 5,000 "Barrister's Opinion" documents. Despite a lower success rate for the "Incident Date" (due to more than 20% of documents omitting this information), the critical information is accurately extracted by the AI in the vast majority of cases.
| Extracted Data | Accuracy |
|---|---|
| Claimant Name | 99% |
| Defendant Name | 95% |
| Barrister Name | 98% |
| Report Data | 99% |
| Incident Date | 75% |
| Probability of Success | 99% |
Built with flexibility in mind
AxisOps' document classification and validation solution has been designed with versatility at its core. As a result, it is possible to:
- Add more document types into the mix
- Add new validation checks for a specific document
- Automatically re-train the AI when more data is collected
As such, the technology developed by AxisOps can be applied to multiple use cases, beyond just the LegalTech sector.
Closing thoughts
With classification and validation capabilities for both structured and unstructured documents, AxisOps has created a product that streamlines a previously time-consuming process. Our solution is versatile and can be applied to many other document-based workflows.
Could your business benefit from automated processing of structured or unstructured data? AxisOps' AI expertise could be the solution you are looking for.
Let's talk AI
Do you have big ideas for leveraging AI?
AxisOps are experts in the delivery of bespoke AI solutions, versatile Neural Networks and GenAI integration.
Start your AI journey